Számos esetben igényként merülhet fel egy adathalmaz valamilyen ismérv szerinti sorba rendezése. Például ha a szabványos könyvtár itertools moduljának groupby() függvényét akarjuk használni, akkor a helyes működéshez az argumentumként átadott adatsorozatnak rendezettnek kell lenni. A sorba rendezést megtehetjük például a sorted() beépített függvénnyel, amely beállítástól függően növekvő vagy csökkenő sorrendben rendezi az értékeket és egy listában adja vissza azokat. Ez mindaddig jól működik, amíg az adatok számossága akkora, hogy ez a rendezett lista befér a számítógép memóriájába.
Mi van azonban akkor, ha olyan nagy adathalmazzal kell dolgozni, amely már nem tölthető be a memóriába a rendezéshez?
Ebben az esetben olyan módszert kell alkalmazni, amely a rendezés folyamán a háttértárat is használja és a rendezett adatok is egy fájlban fognak tárolódni. Mivel tehát ilyenkor a rendezéshez nem csak a belső memóriát, hanem a külső háttértárat is használjuk, ezért az ilyen eljárást külső rendezésnek (external sorting) nevezik. Ennek megfelelően az olyan adatrendezést, amely csak a számítógép memóriájában történik belső rendezésnek (internal sorting) hívják.
A külső rendezés – mivel többszöri háttértárba írás és olvasás történik – természeteseb lassúbb a belső rendezésnél, ami úgy is felfogható, hogy ez az ára annak, hogy a nagy adathalmazunk rendezése egyáltalán megvalósítható.
A következő ábrán a külső rendezés, pontosabban a külső, összefésüléses eljáráson alapuló rendezés (external merge sort) elvét és főbb lépéseit láthatjuk. Az egyes lépések számokkal jelennek meg és az ábra alján olvasható a szöveges kifejtésük.
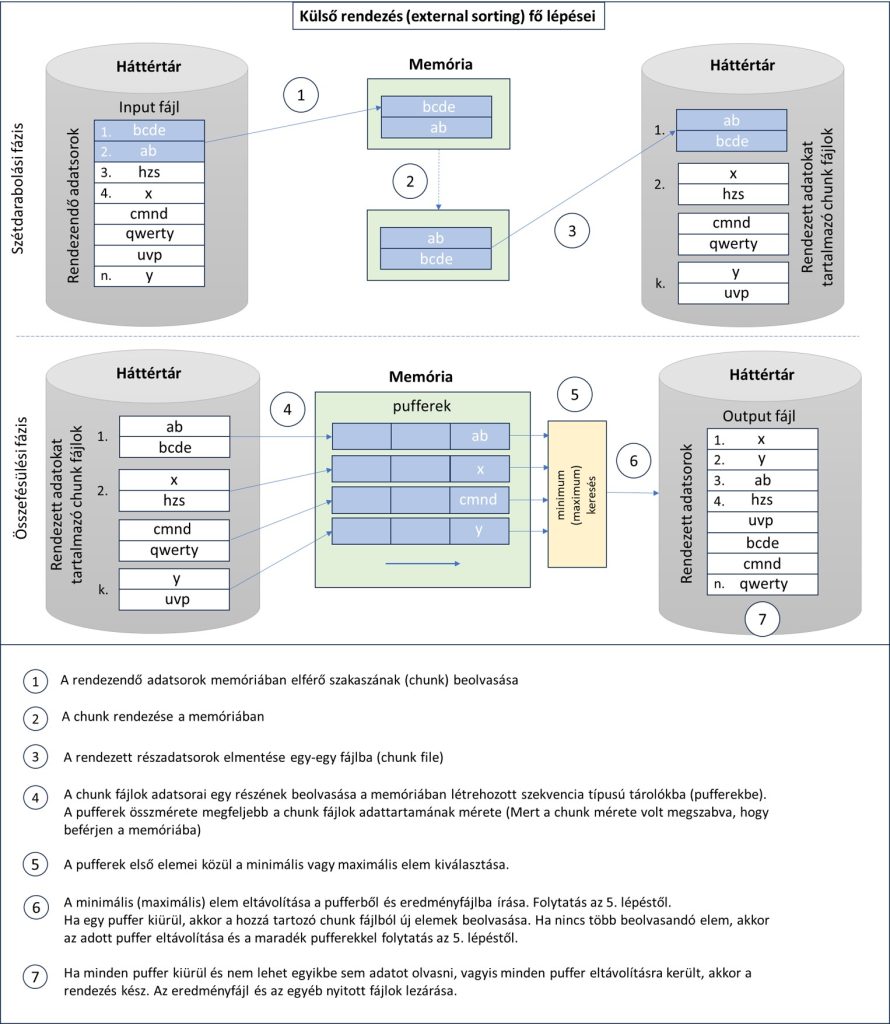
Most egy olyan sort_large_dataset nevű függvényt készítünk, amely az ábrán bemutatott elvet követve egy adott nevű fájl soraiként tárolt véletlenszerű karakterláncokat képes valamilyen ismérv (pl. hossz) szerint sorban rendezni, és a rendezett adatokat tartalmazó fájlt egy megadott nevű fájlba menteni.
Ahhoz, hogy a függvényt tesztelni tudjuk, először létrehozunk egy nagyméretű fájlt a véletlenszerűen előállított karakterláncokkal. Ezek generálásához használjuk az előző, „Véletlenszerű karakterláncok előállítása” című bejegyzésben mutatott függvények egyikét, amely karakterismétlődést is megenged az előállított karaktersorozatokban. Alább látjuk, hogy e függvényt használva hogyan állítunk elő egy 100 millió sort tartalmazó kb 1GB méretű szövegfájlt, amelynek neve dataset.txt.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
from random import choice, choices from itertools import chain from typing import Iterable from pathlib import Path def generate_random_strings(number_of_strings: int, lengths: Iterable, *iterables_of_codepoints): """Egy olyan generátorobjektummal tér vissza, amely az első argumentumban megadott darabszámú karakterláncot állít elő véletlenszerű hosszokkal. Ugyanazon hossz többször is szerepelhet. A lehetséges hosszokat a második argumentum mint iterálható objektum elemei határozzák meg. Egy adott hosszúságú karakterlánc olyan karaktereket tartalmaz, amely a harmadik vagy további argumentumokként felsorolt iterálható objektumokkal definiált Unicode kódpontoknak megfelelő karakterekből véletlenszerűen lesznek kiválasztva. Egy adott karakterláncban azonos karakterek megengedettek. """ # A generált karakterláncok lehetséges hosszai. lengths = tuple(lengths) # A generált karakterláncokban megengedett karakterek Unicode kódpontjai. codepoints = tuple(chain(*iterables_of_codepoints)) return (''.join(map(chr, choices(codepoints, k=choice(lengths)))) for _ in range(number_of_strings)) input_file_path = Path('dataset.txt') # A véletlenszerűen generált karakterláncokat ebbe a fájlba mentjük. number_of_random_strings = 100_000_000 # A rendezendő adatfájlban ennyi sor lesz, mert egy karakterlánc egy sor. # Mindene egyes véletlenszerűen generált karakterláncot a fájl egy soraként mentjük el. # A karakterláncok hossza minimum 1, maximum 15. A generált karakterláncokban a magyar abc kis- és nagybetűi szerepelnek. with open(input_file_path, 'w', encoding='UTF-8', newline='\n') as f_dataset: f_dataset.writelines((s + '\n' for s in generate_random_strings(number_of_random_strings, range(1, 16), range(97, 123), range(65, 91), {225, 233, 237, 243, 246, 337, 250, 252, 369}, {193, 201, 205, 211, 214, 336, 218, 220, 368}))) |
E fájl adatainak rendezését végző sort_large_dataset() függvény definíciója a következő. A megértést a részletes kommentek és a fenti ábra segítik. A működéshez Python 3.12+ verzió szükséges.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 |
from itertools import count, groupby from pathlib import Path from collections import deque from tempfile import TemporaryDirectory # Python 3.12+ szükséges. def text_file_char_count(file_path: str | Path) -> int: """Visszaadja a megadott fájlban tárolt karakterek számát.""" file_size = Path(file_path).stat().st_size # A fájl mérete bájtban. # A memóriába egyszerre beolvasható karakterek számát becsüljük úgy, hogy a fájlméret tizedét vesszük és # minden karaktert 4 bájt méretűnek feltételezünk. max_chars_read = int(file_size / 10 / 4) character_count = 0 with open(Path(file_path), 'r', encoding='utf8', newline='\n') as f: while chars := f.read(max_chars_read): character_count += len(chars) return character_count def sort_large_dataset(input_file_path: str | Path, output_file_path: str | Path, sort_func=None, reverse=False, tempdir=True, max_chunk_size_in_megabyte=10): """Az első argumentumban megadott szövegfájl soraiként szereplő karakterláncokat rendezi a sort_func függvény által meghatározott ismérv szerint növekvő sorrendben. Ha a reverse True, akkor csökkenő sorrendben. A rendezett adatokat a második argumentummal megadott fájlba lesznek mentve. Ha a tempdir True értékű, akkor a közbenső munkafájlok nem maradnak meg. Ha értéke False, akkor a munkafájlok egy létrehozott TMP nevű mappában lesznek tárolva, ami a függvény lefutása után is megmarad. Új hívás esetén a TMP mappa korábbi tartalma törlődik. A közbenső munkafájlok alapértelmezettől eltérő méretét az utolsó argumentummal változathatjuk meg megabájtban megadva. """ input_file_character_count = text_file_char_count(input_file_path) # A rendezni kívánt fájlban tárolt karakterek száma. input_file_size = Path(input_file_path).stat().st_size # A rendezni kívánt fájl mérete bájtban. # ----- Szétdarabolási fázis: a rendezett részadatokat tartalmazó fájlok (chunk fájlok) előállítása ----- # Legfeljebb ekkora méretű listát (chunk list) engedünk a memóriában rendezni a sort() metódussal, amelynek eredményét # ki fogjuk írni egy fájlba (chunk file). max_chunk_size = int(max_chunk_size_in_megabyte * 1024 ** 2) # bájt # Meghatározzuk, hogy a rendezendő adatfájlból egyszerre mennyi karaktert olvasunk be (ami általában több sort jelent). # Ezt az értéket a rendezendő fájl karakterszámából a chunk list és a rendezendő fájl méretének arányában szűmoljuk. chunkfile_chars_limit: int = int(max_chunk_size / input_file_size * input_file_character_count) # A tempdir argumentum értékétől függően a chunk fájlokat vagy egy ideiglenes könyvtárban hozzuk létre, ami a # függvényből való kilépéskor törlődik a tartalmával együtt, vagy egy TMP nevű mappa jön létre, ami a függvény # végrehajtása után is megmarad a benne levő fájlokkal együtt. Ez tesztelést és utólagos elemzést tesz lehetővé. if tempdir: tempdir_obj = TemporaryDirectory(dir=Path(r'.'), delete=False) chunk_files_folderpath = Path(tempdir_obj.name) else: chunk_files_folderpath = Path('TMP') chunk_files_folderpath.mkdir(exist_ok=True) # Ha a rendezett részadatokat tartalmazó chunk fájlok tárolására szolgáló mappa nem üres, akkor töröljük a tartalmát. for file in chunk_files_folderpath.glob('*'): file.unlink() # A rendezni kívánt fájlból beolvassuk a meghatározott hosszúságú szakaszokat egy listába (chunk_list). # E lista elemeit rendezzük az sort_func argumentumban megadott függvény által meghatározott ismérv szerint. # A rendezett lista elemeit egy chunk fájlba mentjük. with open(Path(input_file_path), 'r', encoding='utf8', newline='\n') as f_input: chunk_file_counter = count(1) # A létrejövő chunk fájlokat számolja. while chunk_list := f_input.readlines(chunkfile_chars_limit): chunk_list.sort(key=sort_func, reverse=reverse) with open(chunk_files_folderpath / Path(f'chunkfile{str(next(chunk_file_counter))}.txt'), 'w', encoding='utf8', newline='\n') as chunkfile: chunkfile.writelines(chunk_list) # --- Összefésülési fázis: a rendezett adatokat tartalmazó chunk fájlokból egy olyan eredményfájl előálítása, amelyben az összes adat rendezett --- # Egy új üres kimeneti eredményfájlt hozunk létre akár létezett, akár nem. output_file_path = Path(output_file_path) if output_file_path.exists(): output_file_path.unlink() output_file_path.touch() # Az új üres fájlt megnyitjuk hozzáfűzés módban. out_file_obj = open(output_file_path, 'a', encoding='utf8', newline='\n') # A chunk fájlokat tartalmazó mappában levő összes fájlt olvasásra megnyitjuk. sorted_chunk_fileobjects = [file.open('r', encoding='utf8', newline='\n') for file in chunk_files_folderpath.glob('chunkfile*.txt')] # Beállítjuk azt a maximális karakterszámot, amelynek megfelelő számú elemet a chunk fájlok számának megfelelő pufferek mindegyike # tárolhat. Ez a chunkfile_chars_limit osztva a chunk file-ok számával max_chars_read_from_chunk_files: int = int(chunkfile_chars_limit / (next(chunk_file_counter) - 1)) # darab karakter. # Minden chunk fájlhoz társítunk egy puffert, amit kétvégú sor (deque) konténerrel valósítunk meg. # A puffereket feltöltjük a chunk fájlokból beolvasott első adaggal. buffers_chunk_files = [(deque(chunk_file.readlines(max_chars_read_from_chunk_files)), chunk_file) for chunk_file in sorted_chunk_fileobjects] while buffers_chunk_files: # Mivel az időközben kiürült puffereket töröljük, ezért akkor állunk le, ha nincs már puffer # Vesszük a pufferek első elemét. current_examined_items = (buff[0] for buff, _ in buffers_chunk_files) # Megvizsgáljuk, hogy ezek közül melyik a minimális (maximális). item = min(current_examined_items, key=sort_func) if not reverse else max(current_examined_items, key=sort_func) # A minimum (maximum) értéket kiírjuk a kimeneti eredményfájlba. out_file_obj.write(item) # Meghatározzuk, hogy melyik puffer első eleme volt a kiírt item. E puffer első elemét eltávolítjuk. for buffer, chunk_file in buffers_chunk_files: if buffer[0] == item: buffer.popleft() # Ha az elemetávolítás után üres lesz a buffer, akkor feltöltjük. if not buffer: buffer.extend(chunk_file.readlines(max_chars_read_from_chunk_files)) # Ha már nincs több beolvasható adat, amivel fel lehetne tölteni a puffert, és így az üres marad, akkor # töröljük ezt a pufferek nyilvántartásából. if not buffer: buffers_chunk_files.remove((buffer, chunk_file)) break # A összes chunk fájlt bezárjuk. for fileobj in sorted_chunk_fileobjects: fileobj.close() # A kimeneti eredményfájlt lezárjuk. out_file_obj.close() # Ha ideiglenes könyvtár lett létrehozva, akkor azt eltávolítjuk a tartalmával együtt. if tempdir: tempdir_obj.cleanup() |
A függvényt az alábbi kódsorokkal teszteljük.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
# TESZT input_file_path = Path('dataset.txt') # A rendezendő adatokat tartalmazó fájl. output_file_path = Path('sorted_dataset.txt') # A rendezett adatokat tartalmazó fájl. # A rendezés végrehajtása. sort_large_dataset(input_file_path, output_file_path, sort_func = len, reverse = False, tempdir=True, max_chunk_size_in_megabyte=100) # Ellenőrizzük, hogy a rendezetlen és rendezett adatokat tartalmazó fájl mérete azonos. print('A rendezendő fájl mérete: {:,.2f} kB'.format(input_file_path.stat().st_size / 1024)) print('A rendezett fájl mérete: {:,.2f} kB'.format(output_file_path.stat().st_size / 1024)) # Mivel már rendezetten állnak elő az adatok (karakterláncok), így tudjuk azokat a groupby() függvénnyel csoportosítani. # A csoportosítással most azt nézzük meg, hogy adott karakterlánchossz hányszor fordul elő. with open(output_file_path, 'r', encoding='UTF-8', newline='\n') as f_output: grouped_by_len = {k: sum(1 for _ in iterator) for k, iterator in groupby((s[:-1] for s in f_output), key=len)} # A csoportosított adatokat kiírva láthatjuk, hogy az egyes hosszok gyakorisága közel egyenlő, vagyis a hosszok egyenletes eloszlásúak. print(grouped_by_len) # Ha az egyes hosszokhoz tartozó gyakoriság értékeket összeadjuk, akkor megkapjuk az összes karakterlánc számát. # Ennek egyezni kell a rendezetlen fájl sorainak számával. print('A rendezett fájl sorainak száma: {:_}'.format(sum(grouped_by_len.values()))) # Eredmények: # A rendezendő fájl mérete: 1,079,733.62 kB # A rendezett fájl mérete: 1,079,733.62 kB # {1: 6669647, 2: 6666426, 3: 6663643, 4: 6662386, 5: 6669571, 6: 6667494, 7: 6671073, 8: 6666827, # 9: 6669221, 10: 6664562, 11: 6667095, 12: 6665419, 13: 6669616, 14: 6663141, 15: 6663879} # A rendezett fájl sorainak száma: 100_000_000 |
A rendezés eltart pár percig, és utána a hosszuk szerint rendezett karakterláncok a sorted_dataset.txt fájlban állnak elő. A helyes működés első ellenőrzőpontja, hogy a két fájl mérete egyezik-e. Ha nem, akkor biztos, hogy nem jó valami. Megnyugtató, hogy esetünkben ezek egyeznek. További teszthez a már említett groupby() függvényt használjuk. Ezzel azt nézzük meg, hogy adott karakterlánchossz hányszor fordul elő. Látható, hogy ez egyenletes eloszlású. Ezt is vártuk, hiszen a karakterlánc-előállító függvényben használt choice() egyenletes eloszlást produkál. A fájl sorainak ellenőrzéséhez pedig egyszerűen a hosszgyakoriságok összegét kell venni. Ez is egyezik a rendezendő adatfájl sorainak számával.
A forráskódok elérhetők a https://github.com/pythontudasepites/external_sorting linken is.
E bejegyzésben elsődlegesen a fájlkezelés, valamint speciális iterátorok és konténerek voltak a középpontban. Ezekkel a Python tudásépítés lépésről lépésre című e-könyvben részletesen a „Mentsük, ami menthető! – fájlok és mappák” fejezet valamint a „Készétel fogyasztás – a szabványos könyvtár moduljainak használata” fejezet „Speciális iterátorok” és „Speciális konténer típusok” alfejezetei foglalkoznak.