Gráfokat több módon lehet matematikailag ábrázolni. A leggyakoribb reprezentációk a szomszédsági mátrix és a szomszédsági lista. Ezeket mutatja a következő ábra:
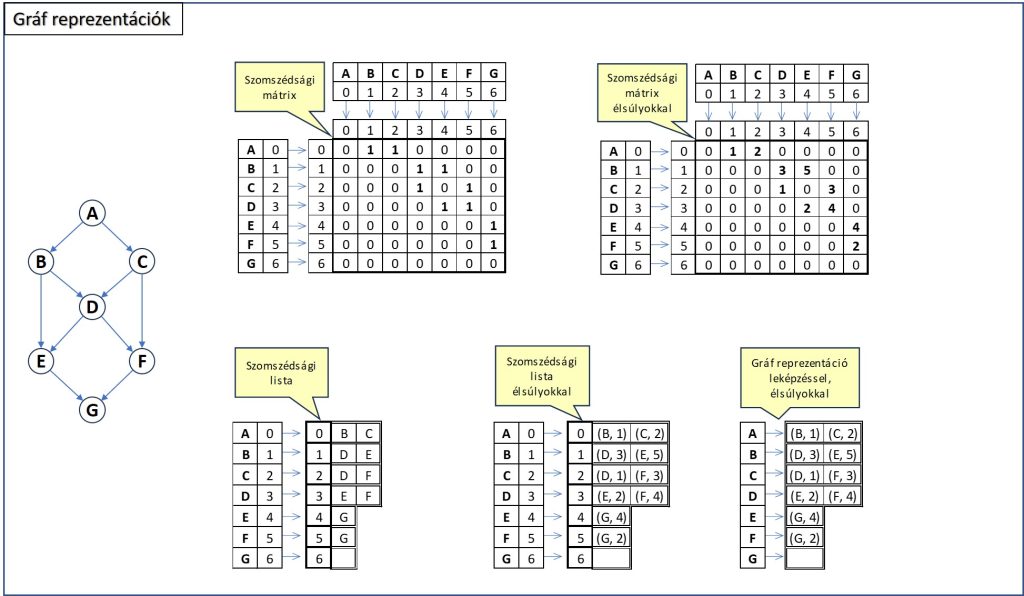
A szomszédsági mátrixban a gráfban szereplő összes csúcsot (vertex) számba vesszük és megnézzük, hogy egy adott csúcsnak mely más csúcsok a közvetlen szomszédai. A vizsgált csúcsok a mátrix sorai, a szomszédos csúcsokat az oszlopok azonosítják. Ha egy vizsgált csúcsnak vannak szomszédai, akkor az adott sor és a megfelelő oszlopok találkozásánál a cellákba egy 0-tól eltérő érték kerül. Ez alapesetben 1, de ha a gráf élei (edge) egymáshoz képest súlyozottak, akkor a súlyértékek kerülnek a szomszédsági mátrix celláiba. Az ábrán látható gráf esetében például az A csúcsnak a B és C közvetlen szomszédja, ezért kerül a mátrix első sorában a második és harmadik oszlop celláiban 0-tól különböző érték.
A szomszédsági listában egy adott csúcs egy lista adott indexéhez tartozik. A lista ezen indexpozíciójában levő eleme egy konténer (adatszerkezet), amely a szomszédos csúcsok azonosítóit tartalmazza. Ha az élek súlyozottak, akkor a konténer a csúcsazonosító-élsúly párokat tárolja. Mivel a szomszédok sorrendje nem releváns információ, ezért a konténer lényegében bármilyen típusú lehet, amely képes vagy a csúcsazonosítókat, vagy a csúcsazonosító-élsúly párokat tárolni.
A szomszédsági mátrix és lista közvetlenül akkor használható, ha a csúcsok címkézése indexszámokkal történik, hiszen ekkor a hivatkozott csúcsok egyben a mátrix sor- és oszlopindexei, illetve a listaindexek. A gyakorlatban azonban az egész számoktól eltérő azonosító vagy, ahogy gráfok esetén mondják, címke (label) előfordulhat. Ilyenkor a csúcsok címkéihez hozzá kell rendelni az indexeket, hogy a szomszédsági mátrixot vagy listát használni lehessen. Ha ebben az esetben a szomszédsági listát egy kicsit jobban megnézzük, akkor rájöhetünk, hogy a csúcscímke->index->konténer megfeleltetések lényegében egy leképzést jelentenek, és egy szótárobjektummal megvalósíthatók. Ez látható az ábra jobb alsó részében. Ez egy gyakori megvalósítási módja a mátrixoknak, mert a gyakorlatban előforduló feladatok nagy részében az élek számának az aránya a lehetséges élszámhoz képest nem nagy. Ekkor – mint például az ábra példagráfja esetében is – a szomszédsági mátrix ritka, azaz relatíve sok a 0 elem. Ezt pedig felesleges tárolni. Viszont leképzéssel, azaz szótárobjektummal megvalósítva csak az érdemi adatokat tároljuk.
Szótárral megvalósított gráf ugyan önmagában használható, de egy összetettebb program részeként már nem kényelmes a használata, és kevésbé olvasható kódot eredményez. Ezért célszerű a gráfot egy osztályban definiálni, és abban alkalmazni a gráfot reprezentáló szótárt. A gráf osztályában azután bármilyen, az adott feladathoz szükséges metódust definiálhatunk.
Hasonló a helyzet a csúcsokkal is. Bár az ábrán látható reprezentációkban csak a csúcscímkék szükségesek, de előfordulhatnak helyzetek, amikor egyéb adat is társul a csúcshoz. Ezért célszerű a gráf csúcsaihoz is egy megfelelő osztályt definiálni.
A gráfot meghatározó osztály sokféleképpen megvalósítható. Egy lehetséges definíciót láthatunk alább. Ez a változat egyben a collections modul defaultdict szótárának egy gyakorlati alkalmazására is egy példa. A megértést a részletes kommentek segítik.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
from collections import defaultdict class Vertex: def __init__(self, label, data=None): self.label = label self.data = data def __repr__(self): args = f'{self.label}, {self.data}' if self.data else f'{self.label}' return f'{type(self).__name__}({args})' class Graph: def __init__(self): self.vertices: dict[str, Vertex] = dict() self.neighbors: dict[str, set[tuple[str, int | float]]] = defaultdict(set) def __str__(self): w = max(len(vname) for vname in self.neighbors) graph_string = [] for vertex_label, neighbors in self.neighbors.items(): nbrs = str(neighbors).strip("{}") if neighbors else '' graph_string.append(f'{vertex_label:{w}} {chr(0x279E)} {nbrs}\n') return ''.join(graph_string) def add_connection(self, start_vertex_label: str, end_vertex_label: str, weight=1): """A megadott kezdő- és végcsúcs közötti élt határozza meg a gráfban. Opcionálisan az élhez rendelhető egy, az alapértelmezett értéktől eltérő súly is. Ha a létrehozandó élhez tartozó csúcsok nem léteznek még, akkor azokat létrehozza. """ # Hozzáadjuk az adott induló csúcshoz tartozó halmazhoz a végcsúcs és az él súlyából képzett párost. # Ha az adott csúcs még nincs a szótárban, akkor felveszi, és rögtön hozzárendel egy halmaz konténert. self.neighbors[start_vertex_label].add((end_vertex_label, weight)) # Felvesszük a szomszédságot leíró szótárba a végcsúcsot, ha az nem létezik még, és amihez # rögtön hozzárendelünk egy halmaz konténert. self.neighbors[end_vertex_label] # A tényleges csúcs objektumokat is létrehozzuk és eltároljuk, ha még nem léteznek. if start_vertex_label not in self.vertices: self.vertices.update({start_vertex_label: Vertex(start_vertex_label)}) if end_vertex_label not in self.vertices: self.vertices.update({end_vertex_label: Vertex(end_vertex_label)}) def remove_edge(self, start_vertex_label: str, end_vertex_label: str): """A megadott kezdő- és végcsúcs közötti élt eltávolítja.""" self.neighbors[start_vertex_label] = set(item for item in self.neighbors[start_vertex_label] if item[0] != end_vertex_label) def remove_vertex(self, vertex_label: str): """A megadott csúcsot eltávolítja a gráfból.""" # A csúcs objektumok közül eltávolítjuk a csúcsot. self.vertices.pop(vertex_label) # A szomszédságot leíró szótárból eltávolítjuk a megadott csúcsot. self.neighbors.pop(vertex_label) # Minden olyan csúcs esetén, amelynek szomszédja volt, kivesszük a szomszéd csúcsok közül. for vxl, nbs in self.neighbors.items(): self.neighbors[vxl] = set(item for item in nbs if item[0] != vertex_label) def set_vertex_data(self, vertex_label, vertex_data): """Egy adott csúcshoz értéket rendel.""" if vx := self.vertices.get(vertex_label): vx.data = vertex_data |
A működést a következő tesztesetekkel követhetjük nyomon.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
# TESZT graph = Graph() # A gráf felépítése csúcsokból és azok közötti súlyozott összeköttetésekkel. for vertices_and_weight in ('A-B-1', 'A-C-2', 'B-D-3', 'B-E-5', 'C-D', 'C-F-3', 'D-E-2', 'D-F-4', 'E-G-4', 'F-G-2'): graph.add_connection(*vertices_and_weight.split('-')) print(graph) # Eredmény: # A ➞ ('C', '2'), ('B', '1') # B ➞ ('D', '3'), ('E', '5') # C ➞ ('F', '3'), ('D', '1') # D ➞ ('E', '2'), ('F', '4') # E ➞ ('G', '4') # F ➞ ('G', '2') # G ➞ # Az A és B csúcs közötti élt eltávolítjuk. graph.remove_edge(*'AB') print(graph) # Eredmény: # A ➞ ('C', '2') # B ➞ ('D', '3'), ('E', '5') # C ➞ ('F', '3'), ('D', 1) # D ➞ ('E', '2'), ('F', '4') # E ➞ ('G', '4') # F ➞ ('G', '2') # G ➞ # Eltávolítjuk a gráfból a D jelű csúcsot. graph.remove_vertex('D') print(graph) # Eredmény: # A ➞ ('C', '2') # B ➞ ('E', '5') # C ➞ ('F', '3') # E ➞ ('G', '4') # F ➞ ('G', '2') # G ➞ # Értéket rendelünk csúcsokhoz. for lbl in 'ABCDEF': graph.set_vertex_data(lbl, ord(lbl)) print(*graph.vertices.values()) # Eredmény: # Vertex(A, 65) Vertex(B, 66) Vertex(C, 67) Vertex(E, 69) Vertex(F, 70) Vertex(G) |
E bejegyzés témájához a Python tudásépítés lépésről lépésre című e-könyv következő részei kapcsolódnak különösen: „Beépített konténerobjektumok”, „Beépített típusok nyilvános metódusai”, és az „Osztály vigyázz! – típuslétrehozás osztályokkal” fejezetek, valamint a „Készétel fogyasztás – a szabványos könyvtár moduljainak használata fejezet „Alapérték előállítással kombinált szótár – defaultdict” alfejezete.