Ha egy adatsor számtani középértékét akarjuk meghatározni, akkor erre a célra használhatjuk a szabványos könyvtár statistics moduljának mean() és fmean() függvényeit. Az átlagolandó adatokat véges számú elemet szolgáltató iterálható objektumként kell megadni a függvényeknek.
Kérdésként merülhet fel, hogy mi a két függvény között a különbség, melyiket válasszuk?
A Python hivatalos dokumentációja szerint az fmean() az adatsor értékeit float típusú számmá konvertálja és az eredmény is float típusú lesz. Gyorsabb számítást eredményez, mint a mean(). E két jellemző miatt szerepel a név elején az f betű, ami egyaránt utalhat a float-ra és a fast (gyors) szóra is. Egyébként a Python 3.11 verziótól kezdve rendelkezik egy opcionális weights paraméterrel is, amellyel lehetővé válik, hogy súlyozott számtani átlagot számítsunk.
A mean() tekintetében azonban a hivatalos dokumentáció meglehetősen szűkszavú. Azt ugyan rögtön lehet látni, hogy ez nem rendelkezik az opcionális weights paraméterrel, de ami a visszaadott átlag típusát illeti, csak az ott szereplő néhány egyszerű példakódból lehet következtetni, hogy a mean() nem csak float típusú eredményt tud szolgáltatni. De, hogy pontosan mikor, milyen esetben kapunk int, float, Fraction vagy Decimal típusú eredményt arról nem kapunk tájékoztatást. Minthogy arról a fontos jellemzőről sem, hogy a mean() pontosabb számítást eredményez, mint az fmean(), és ezért is lassabb. Mindezt csak a forráskód tanulmányozása és egyéni összehasonlító tesztek alapján tudhatjuk meg.
E jellemzőket fogjuk feltárni és alaposabban megismerni a továbbiakban, de nem a forráskód elemzésével, hanem úgy, hogy annak elvi megközelítése alapján egyszerűsített formában leutánozzuk a mean() függvény működését egy custom_mean() nevű függvénnyel. Az implementáció egyszerűsítését az jelenti, hogy a custom_mean() az adatsort csak konténerben tudja fogadni ellentétben a mean() függvénnyel, amelynek bármilyen iterálható objektum megadható argumentumként.
Ezek után a custom_mean() függvény megvalósításakor a mean() függvény két lényegi működési részletére kell csak összpontosítani. Az egyik, hogy a kiszámított és visszaadott középérték típusát hogyan kell meghatározni. A másik, hogy hogyan érhető el nagyobb számítási pontosság.
A mean() függvény visszatérési értékének típusa az adatsorban előforduló számtípusok közül azzal egyezik meg, amelyik a legtágabb számhalmazt reprezentálja. Ha az adathalmaz minden eleme int típusú egész szám, de az eredmény nem egész, akkor a visszaadott érték típusa float lesz. E szabályokat foglalja össze a következő ábra.
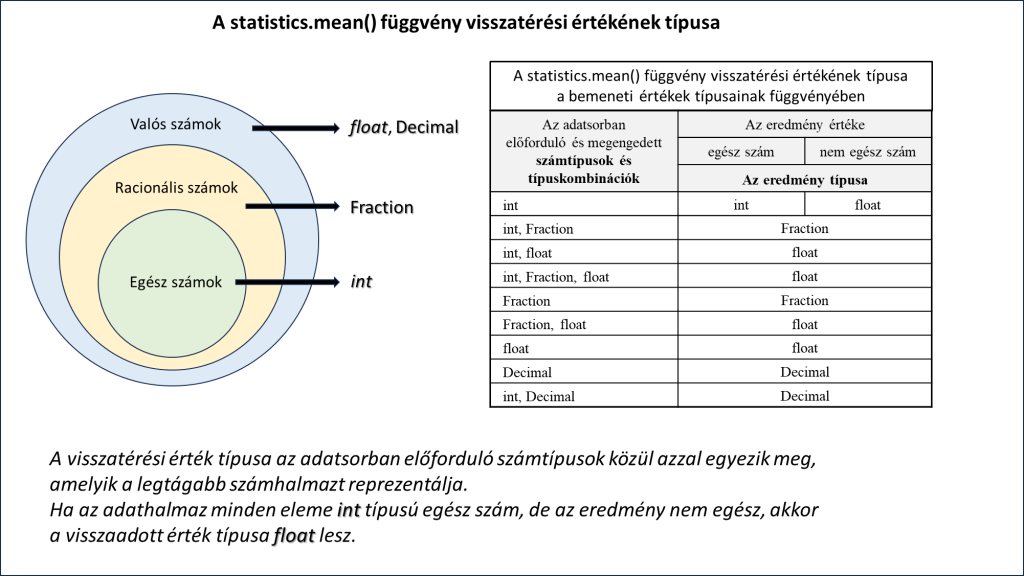
A pontosság növelése pedig úgy történik, hogy az átlagolandó számértékeket a közönséges törteket reprezentáló Fraction típusúvá alakítjuk, mert ekkor a közbenső műveletek tört számot jelentő eredményeinek esetleges kerekítési hibái kiküszöbölhetők. Ugyanakkor, ha az adatsor bármely értéke eleve olyan float típusú szám, amelynél ábrázolási pontatlanság lép fel, akkor azt ez a módszer természetesen nem tudja megszüntetni, csak a közbenső műveletek pontosságát tudja növelni.
Ezen elveknek és követelményeknek megfelelő custom_mean() függvény egy lehetséges megvalósítását láthatjuk alább. A működés megértését a részletes kommentek segítik.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
from decimal import Decimal from fractions import Fraction from math import isclose from typing import Collection class StatisticsError(ValueError): pass def custom_mean(data: Collection[int | float | Fraction | Decimal]) -> int | float | Fraction | Decimal: """A megadott numerikus adatsor középértékét (számtani átlagát) adja vissza. Az értékek típusa int, Fraction és float lehet akár vegyesen is. Lehet Decimal is, de ekkor az adatsorban ettől eltérő típusként csak int fordulhat elő, mert a Decimal a float és Fraction típusokkal nem tud műveleteket végezni. A visszatérési érték típusa az adatsorban előforduló azon számtípussal egyezik meg, amely a legtágabb számhalmazt reprezentálja. Ha az adatsor minden eleme int típusú egész szám, de az eredmény nem az, akkor a visszaadott érték típusa float lesz. Ha az átadott konténer üres, akkor StatisticsError kivétel keletkezik. A statistics.mean() függvényhez hasonlóan a számításokhoz a közbenső kerekítési hibáinak kiküszöbölése érdekében az átlagolandó értékek Fraction típusúvá konvertálódnak. Viszont az implementációt egyszerűsítő korlát, hogy az értékeket konténerben kell megadni. """ if len(data) == 0: raise StatisticsError('Az adatsor legalább egy elemet kell, hogy tartalmazzon.') if float('nan') in data: return float('nan') if float('inf') in data: return float('inf') # Összegyűjtjük az adatsorban szereplő értékek előforduló típusait. types_in_data = {type(x) for x in data} # Ha Decimal szerepel a típusok között, és mellette az int-en kívül van más számtípus is, akkor hibajelzést adunk. # Ha csak Decimal és int szerepel, akkor az eredmény típusának meghatározásához a típushierarchia e kettőből áll. # Ha nincs Decimal típusú szám az adasorban, akkor a típushierarchia int, Fraction és float. if Decimal in types_in_data: if not (types_in_data - {Decimal} == set() or types_in_data - {Decimal} == {int}): raise TypeError('Az adatsorban a Decimal típusú számok mellett legfeljebb int típusúak szerepelhetnek.') type_hierarchy = [int, Decimal] else: type_hierarchy = [int, Fraction, float] return_type = type_hierarchy[max((type_hierarchy.index(tp) for tp in types_in_data if tp in type_hierarchy))] # A számértékeket Fraction típusúvá alakítjuk a pontosabb számításhoz (a közbenső kerekítési hibák kiküszöböléséhez). # Ha az érték float és ábrázolási pontatlansága van (pl. 0.1), akkor azt ez nem szünteti meg. data = [Fraction(*x.as_integer_ratio()) for x in data] avg: Fraction = sum(data) / len(data) if return_type is Decimal: return Decimal(avg.numerator) / Decimal(avg.denominator) # Ha az adatsor minden eleme egész, de az átlag nem az, akkor a visszaadott érték típusa float lesz. if return_type is int and not isclose(int(avg) - avg, 0, abs_tol=1e-15): return_type = float # Ha nem minden érték egész szám, akkor az adatsorban előforduló azon számtípussal térünk vissza, amely a legtágabb # számhalmazt reprezentálja. return return_type(avg) |
Azt, hogy ez a függvény helyesen utánozza a mean() függvény működését a következő programsorokkal teszteljük.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
from typing import Callable from statistics import mean, fmean def calc_and_print_mean(mean_function: Callable, data_sequence: Collection): """A megadott függvénnyel kiszámítja a második argumentumként megadott adatsorozat számtani középértékét és kiírja azt vagy hibajelzést ad, ha az adatsorban nem megfelelő típusú számok szerepelnek. """ txt = f"{mean_function.__name__}():" try: m = mean_function(data_sequence) print(f'\t{txt:>15} = {m} ({type(m).__name__})') except TypeError: print(f'\t{txt:>15} Hiba - Nem összeillő típusok a sorozatban {[repr(x) for x in data_sequence]}') # TESZT tested_functions = [custom_mean, mean, fmean] # Tesztadatsorok. data_sequencies = [(2, 4), (2, 4.0), (2, Fraction(4, 1)), (2.0, Fraction(4, 1)), (Fraction(2, 1), Fraction(4, 1)), (2.0, 4.0), (2, Fraction(5, 1), 11.0), (2, 5), (2, 5.0), (2, Fraction(5, 1)), (2.0, Fraction(5, 1)), (Fraction(2, 1), Fraction(5, 1)), (2.0, 5.0), (2, Fraction(5, 1), 6.5), (Decimal(2), 4), (Decimal(2), 4.0), (Decimal(2), Fraction(4, 1)), (Decimal(2), Decimal(4)), (Decimal(2), 5), (Decimal(2), 5.0), (Decimal(2), Fraction(5, 1)), (Decimal(2), Decimal(5)) ] for seq in data_sequencies: print(f'Elemek típusa: {", ".join([type(num).__name__ for num in seq]).strip("[]")}') print('Eredmény és típusa:') for func in tested_functions: calc_and_print_mean(func, seq) print() |
Az eredményeket az alábbi ábrák mutatják. A helytakarékosság okán az egymás alá írt eredménysorokat két egymás melletti blokban tüntettük fel aszerint, hogy az eredmény egész vagy nem egész szám.


Amint az látható, a mean() és custom_mean() ugyanazt az eredményt adja azonos bemeneti adatsorozatra.
Most vizsgáljuk meg az alábbi tesztprogrammal, hogy futási idő tekintetében mit kapunk az fmean(), mean() és custom_mean() esetén.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
from timeit import timeit from random import random test_dataset = [random() for _ in range(1000)] functions = [custom_mean, mean, fmean] running_times = {func.__name__: timeit('func(test_dataset)', globals=globals() | locals(), number=1) for func in functions} for func_name, exec_time in dict(sorted(running_times.items(), key=lambda t: t[1])).items(): print(f'{func_name:12}: {exec_time:.2e}') # Futási idő eredmények: # fmean : 9.60e-06 # mean : 4.83e-04 # custom_mean : 2.79e-03 |
Az eredmények visszaigazolják, hogy az fmean() jelentősen gyorsabb, mint a mean(). És azt is látjuk, hogy a saját készítésű custom_mean() számol a leglassabban.
Mindebből azt a következtetés lehet levonni, hogy a custom_mean() elsősorban arra jó, amire szántuk, vagyis a mean() függvény működésének megértésére, gyakorlati alkalmazásra kevésbé alkalmas egyrészt a futási idő miatt, másrészt azon korlát miatt, hogy nem adható meg tetszőleges iterálható objektum. A mean() és fmean() közötti választást az határozza meg, hogy mennyire számít a futási idő és a pontosság. Nagyméretű adatsor esetén, ahol a futási idő már érzékelhető mértékű, az fmean() használata lehet előnyösebb. Rövidebb adatsornál érdemes lehet a mean() alkalmazásának megfontolása, mert ekkor pontosabb eredményt kaphatunk. És, ha az eredmény nem float, akkor a pontosabb ábrázolást biztosító számtípust egy következő feldolgozási lépéshez továbbvihetjük.
Bár a mean() és fmean() pontosságbeli eltérését többször említettük, de azt még nem vizsgáltuk, hogy ez milyen mértékű. Ezt a következő függvénnyel teszteljük. Ennek célját a függvény dokumentációs karakterlánca (docstring) részletezi, működésének megértését pedig a kódban elhelyezett kommentek segítik.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
from decimal import getcontext def compare_mean_accuracy(sequence_length: int, trials: int = 1000): """ Megvizsgálja, hogy a statistics.mean() és a statistics.fmean() milyen gyakran ad eltérő eredményt, illetve amikor eltérnek, melyik van közelebb a decimális aritmetikával (Decimal típus) számolt referencia számtani átlaghoz. A függvény egy megadható hosszúságú adatsorozaton végez vizsgálatot. Az eltérések gyakoriságának megállapításához a kísérletek számát is meg lehet adni. Paraméterek: - sequence_length: a vizsgált adatsor hossza - trials: a kísérletek száma Visszatérési értékek: - differing_ratio: annak aránya, hogy a mean() és a fmean() eltérő eredményt ad. - fast_mean_worse_ratio: annak aránya, hogy az fmean() pontatlanabb eredményt ad, mint a mean(). """ # A középérték-referencia értékénak decimális artimetikával történő számításához nagy pontosságot állítunk be. getcontext().prec = 100 # Annak számlálója, hogy az fmean() és mean() hányszor tért el a kísérletek során. differing_mean_count = 0 # Annak számlálója, hogy a mean() eredménye a referenciaértékhez képest hányszor volt pontatlanabb, mint az fmean()-é. mean_worse_count = 0 for _ in range(trials): # Véletlen float értékeket tartalmazó tesztadatsor. data = [round(random() * 10 ** 6, 6) for _ in range(sequence_length)] # Az adatok Decimal típusú számként. A float kerekítési hibák kiküszöböléséhez az eredeti értékeket # a Decimal konverzió előtt karakterláncokká alakítjuk. data_decimal = [Decimal(str(x)) for x in data] exact_sum: Decimal = sum(data_decimal) # A két különböző függvénnyel számolt középérték. arithmetic_mean: float = mean(data) fast_arithmetic_mean: float = fmean(data) try: # A két eredménynek általában egyenlőnek kell lenni. assert arithmetic_mean == fast_arithmetic_mean except AssertionError: # Ha nem egyenlőek, akkor ezt az eseményt feljegyezzük, és megnézzük az eltéréseket a referenciától. differing_mean_count += 1 exact_mean: Decimal = exact_sum / sequence_length # Az átlag pontos referenciaértéke. # Megvizsgáljuk, hogy a mean() jobban tér-e el a pontos értéktől, mint az fmean(). if abs(exact_mean - Decimal(arithmetic_mean)) > abs(exact_mean - Decimal(fast_arithmetic_mean)): mean_worse_count += 1 differing_ratio = differing_mean_count / trials fast_mean_worse_ratio = 1 - (mean_worse_count / trials) return differing_ratio, fast_mean_worse_ratio # TESZT print(f'{'Adatsor hossza':^18}{"Nemegyezőség aránya":^23}{"fmean() pontatlanabb":^24}') print(f'{"=" * 14:^18}{"=" * 19:^23}{"=" * 20:^24}') for seq_length in [10, 100, 1000, 10_000, 100_000]: error_ratio, fmean_worse_ratio = compare_mean_accuracy(seq_length) print(f"{seq_length:>9}{error_ratio:23.1%}{fmean_worse_ratio:24.1%}") # Eredmények 1000 adatsorozat esetén: # Adatsor hossza Nemegyezőség aránya fmean() pontatlanabb # ============== =================== ==================== # 10 28.7% 95.2% # 100 27.7% 98.3% # 1000 25.6% 99.4% # 10000 40.0% 99.7% # 100000 33.1% 100.0% |
A kiírt eredménysorokból érdemi következtetéseket vonhatunk le. Ha a példafuttatás szerint 1000 adatsorozatot vizsgálunk, akkor az esetek 25-40%-ában az fmean() és mean() nem ad azonos eredményt. És az is jól megfigyelhető, hogy minél hosszabb az adatsor, összességében annál nagyobb arányban mutat kisebb pontosságot az fmean() a mean() függvénnyel szemben.
Ebben a bejegyzésben a számos alapvető nyelvi elem mellett elsősorban a szabványos könyvtár statistics, random, decimal, fractions és math moduljainak osztályait és függvényeit használtuk. Mindezekről a Python tudásépítés lépésről lépésre című e-könyv „Készétel fogyasztás – a szabványos könyvtár moduljainak használata” fejezet „Matematikai számítások támogatása” című alfejezetében lehet részletesen olvasni.