Ha mértékegységekkel dolgozunk, akkor szükség lehet egy olyan függvényre, amely ellenőrzi, hogy az argumentumként megadott karaktersorozat egy, a mértékegységek nagyságrendjét meghatározó SI előtag jele-e, és ha igen, akkor visszaadja az előtag által jelölt szorzótényezőt. Ez elég egyszerű feladatnak tűnik, mert az előtagjel és szorzótényező megfeleltetéseket egy szótárban kell tárolni, és a függvény e szótárnak a függvény argumentumhoz mint kulcshoz tartozó értékét szolgáltatja, ha a kulcs a szótárban található. Ha nem, akkor egy kivételt dob. Ezt látjuk alább:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
SI_PREFIXES = {'p': 1e-12, 'n': 1e-09, 'μ': 1e-6, 'm': 1e-3, 'c': 1e-2, 'd': 1e-1, 'T': 1e+12, 'G': 1e+09, 'M': 1e+6, 'k': 1e+3, 'h': 1e+2, 'da': 1e+1} def get_prefix_multiplier(prefix: str) -> float: """Visszaadja az argumentumhoz mint SI előtaghoz tartozó szorzószámot.""" if prefix in SI_PREFIXES: return SI_PREFIXES[prefix] raise ValueError(f'Nem érvényes SI előtag: {prefix_symbol}') if __name__ == '__main__': for prefix_symbol in ('p', 'n', 'µ', 'm', 'c', 'd', 'da', 'h', 'k', 'M', 'G', 'T'): try: print('{:2} {:.0e}'.format(prefix_symbol, get_prefix_multiplier(prefix_symbol))) except ValueError as ve: print(ve) # Eredmények: # p 1e-12 # n 1e-09 # Nem érvényes SI előtag: µ # m 1e-03 # c 1e-02 # d 1e-01 # da 1e+01 # h 1e+02 # k 1e+03 # M 1e+06 # G 1e+09 # T 1e+12 |
A kiírásokból látható, hogy az előtagjelekhez megkapjuk a szorzókat egy kivételével. A µ karakterrel jelölt „mikro” előtag esetén hibajelzést kapunk, mondván, hogy ilyen jel nem szerepel a szótárban. Elsőre ez elég meglepő, hiszen látjuk a µ betűt a szótárban. Mi lehet a gond?
Gyanús lehet, hogy éppen a µ esetén van a probléma, mert az SI előtagjelek közül ez az egyetlen, amely nem a latin ábécéből származik. A többiek ráadásul az ASCII készlet betűi. Lehet, hogy akkor a karakterkészlet körül kell keresni az okokat? Elég valószínű, de ahhoz, hogy megállapítsuk, hogy miért, első menetben egy kicsit tájékozódjuk az SI előtagokról, ezen belül is arról, hogy milyen Unicode karakterrel kell jelölni hivatalosan a micro előtagot. Legyorsabban a Wikipedia „Micro-” szócikkében találjuk meg a választ. Ebből kiderül, hogy a micro előtagra két Unicode karakter is használatos. Az egyik az U+00B5 (MICRO SIGN), a másik az U+03BC (GREEK SMALL LETTER MU). És azt is megtudjuk, hogy ez utóbbi az SI által hivatalosan támogatott karakter.
Ha lekérjük az ord() beépített függvénnyel a szótárban szereplő µ betű és az argumentumként átadott µ karakter kódpontját reprezentáló egész számot, akkor derül ki, hogy mi a probléma. A szótárban az előtagként hivatalosan is támogatott U+03BC kódpontú karakter szerepel, a függvény hívásakor azonban az U+00B5 kódpontú karakter lett bevíve. A hiba okát pedig azért nem látjuk azonnal, mert a vizuális megjelenése a kettőnek azonos.
Ha tudnánk előre, hogy a függvénynek a görög kis mű betűt kell megadni, akkor is némi technikai kényelmetlenségbe ütközhetünk. Ugyanis a normál számítógépbillentyűzeten nincs µ karakter. Csak billentyűkombinációval tudunk ilyet beilleszteni, ami platformfüggő. Windows alatt az Alt gomb lenyomva tartása mellett a numerikus billentyűzeten a 0181 számsort kell beírni. Ezzel azonban a feladatunk szempontjából az a baj, hogy nem az Unicode szerinti görög betűt eredményezi, hanem a MICRO SIGN karaktert. A görög mű betűhöz viszont nincs Alt-kód. Tehát, ha ezt akarjuk megkapni, akkor más megoldást kell keresni.
Egy platformfüggetlen lehetőség, hogy a neten rákeresünk az Unicode GREEK SMALL LETTER MU keresőkifejezéssel, és az ott megjelenő karakterképet kimásoljuk. Ha Windows alatt dolgozunk, akkor egy másik, viszonylag egyszerű megoldás, ha a beépített Character Map alkalmazást elindítjuk és itt keressük meg, majd kimásoljuk. Ezt a módszert mutatja a következő ábra, ahol a teendőket a bekarikázott számok sorrendjében kell végezni.
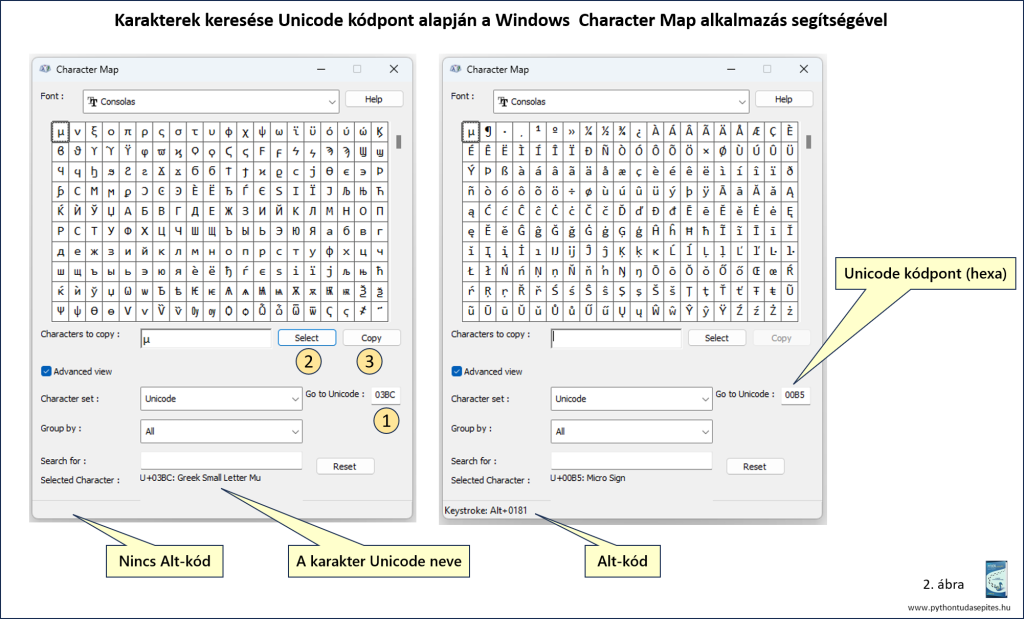
Tovább bonyolítja a helyzetet, hogy az Unicode készletben nem csak ez a két karakter jelenik meg µ karakterként. Az összes, µ karakterképpel rendelkező karakter jellemzőit az alább látható programkóddal íratjuk ki. Itt a karakternevek kinyeréséhez a szabványos könyvtár unicodedata moduljának name függvényét használtuk.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import unicodedata as ud unicode_micro_codepoints = (0x00B5, 0x03BC, 0x1D6CD, 0x1D707, 0x1D741, 0x1D77B, 0x1D7B5) print('{:^15}{:^15}{:^14}{:^45}'.format('Kódpont (hex)', 'Kódpont (dec)', 'Karakterkép', 'Karakternév')) print(chr(0x2015) * 57) for codepoint in unicode_micro_codepoints: print(' {:>05X} {:>17} {:^20} {:<45}'.format(codepoint, codepoint, chr(codepoint), ud.name(chr(codepoint)))) # Kódpont (hex) Kódpont (dec) Karakterkép Karakternév # ――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――― # 000B5 181 µ MICRO SIGN # 003BC 956 μ GREEK SMALL LETTER MU # 1D6CD 120525 𝛍 MATHEMATICAL BOLD SMALL MU # 1D707 120583 𝜇 MATHEMATICAL ITALIC SMALL MU # 1D741 120641 𝝁 MATHEMATICAL BOLD ITALIC SMALL MU # 1D77B 120699 𝝻 MATHEMATICAL SANS-SERIF BOLD SMALL MU # 1D7B5 120757 𝞵 MATHEMATICAL SANS-SERIF BOLD ITALIC SMALL MU |
A karakterek e többértelműsége – vagyis az, hogy hasonló vizuális megjelenéshez különböző absztrakt karakterekhez tartozhatnak – nem csak a µ karakter kapcsán merül fel az Unicode karakterkészletben. És ez a programokban hasonló gondot okozhat, mint a kiinduló függvényünk esetében. Ezen úgy lehetne segíteni, ha a megjelenési formában hasonló karaktereket valamilyen elv szerint „közös nevezőre” lehetne hozni. Ekkor a bemenetként megadott karakterláncokat erre lehetne konvertálni, és így az egyenlőségvizsgálatnál már nem lenne abból adódó eltérés, hogy a szemantikailag vagy vizuális formában hasonló bevitt karakterek különböző kódpontokhoz tartoznak.
A Unicode szabvány e problémát a karakterek kétfajta egyenértékűségének meghatározásával, és ezek alapján történő normalizálással oldja meg. E fogalmakat tekintjük át a következőkben.
Unicode-egyenértékűség és fajtái
Az Unicode-egyenértékűség azt jelenti, hogy bizonyos kódpont-sorozatok lényegében ugyanazt a karaktert képviselik. Az egyenértékű karakterek azonosak vagy hasonlóak. A karaktsorozatok két módon lehetnek egyenértékűek: kanonikusan egyenértékűek vagy kompatibilisek.
A kanonikusan egyenértékű kódpontok megjelenése és jelentése megegyezik. Például az U+0065 (e), amelyet egy, önállóan nem használható, a megelőző karakterhez kapcsolódó ékezetjel, az U+0301 (◌́) követ, kanonikusan egyenértékű az U+00E9 (é) kódponttal. E kettő megjelenésében pontosan megegyezik, és karakterek rendezésekor vagy keresésekor egymással helyettesíthető.
A kompatibilis kódpontok eltérően jelenhetnek meg, de meghatározott kontextusokban azonos jelentéssel bírnak. Például az U+00BD (½) kompatibilis az U+0031 U+2044 U+0032 (1⁄2) karaktersorozattal, de nem kanonikusan egyenértékű. A kompatibilis sorozatok adott alkalmazásokban ugyanúgy használhatók, illetve helyettesíthetők.
Unicode-normalizálás
A Unicode két fajta egyenértékűsége teremti meg annak lehetőségét, hogy a szoftverekben a szövegfeldolgozáskor a keresés és összehasonlítás a tervezettnek megfelelően, helyesen működjön. Ennek feltétele, hogy a feldolgozni kívánt karaktersorozatnak elő tudjuk állítani az egyenértékű változatát.
A karakterláncok egyenértékű sorozatát a normalizálásnak nevezett folyamat határozza meg, amely a karakterláncokat olyan formára alakítja, amelyek közvetlenül összehasonlíthatók.
A Unicode-normalizálás célja tehát, hogy a többféleképpen kódolható karaktereket egyetlen, szabványos formátumra alakítsa. Ezt nevezik az eredeti karaktersorozat normalizált formájának.
A szabvány négy normalizációs formát határoz meg. Ez két szempont együttes alkalmazásának eredménye:
- a normalizálás kanonikus felbontást vagy kompatibilitási felbontást alkalmaz, és
- a normalizált forma az egyenértékű sorozatok lehető legteljesebb felbontásával, vagy összetételével jön létre.
Unicode normalizációs formák
D normalizációs forma (Normalization Form D, NFD):
A karaktersorozat szabvány szerint kanonikusan egyenértékű karakterekre bontása, majd ezek kanonikus rendezése.
KD normalizációs forma (Normalization Form KD, NFKD):
A karaktersorozat szabvány szerint kompatibilisen vagy kanonikusan egyenértékű karakterekre bontása, majd ezek kanonikus rendezése.
C normalizációs forma (Normalization Form C, NFC):
A karaktersorozat szabvány szerint kanonikusan egyenértékű karakterekre bontása, ezek kanonikus rendezése, majd az így kapott sorozat kanonikus összetétele.
KC normalizációs forma (Normalization Form KC, NFKC):
A karaktersorozat szabvány szerint kompatibilisen vagy kanonikusan egyenértékű karakterekre bontása, ezek kanonikus rendezése, majd az így kapott sorozat kanonikus összetétele.
Ha egy karakterhez nem tartozik dekompozíciós leképezés, akkor a karakter változatlan marad.
A kompatibilitási felbontás nem helyettesíti, hanem kiterjeszti a kanonikust: minden kanonikus felbontás kompatibilitási értelemben is megengedett. De nem minden kompatibilitási felbontás kanonikus.
A „felbontás” (decomposition) itt tágabb értelemű fogalom, mert előfordul, hogy egy karakter dekompozíciója egyetlen másik karakterből áll.
Unicode kompatibilitási kategóriák
A karaktersorozatok közötti kompatibilitás több ismérv szerint is meghatározható, amelyek alapján kompatibilitási kategóriák hozhatók létre. Az Unicode e kategóriáknak megfelelő kompatibilitási címkéket rendel a karakterekhez és ezt követően megadja a kompatibilis karaktert vagy karaktersorozatot. A kategóriák és címkék a következő táblázatában vannak felsorolva.
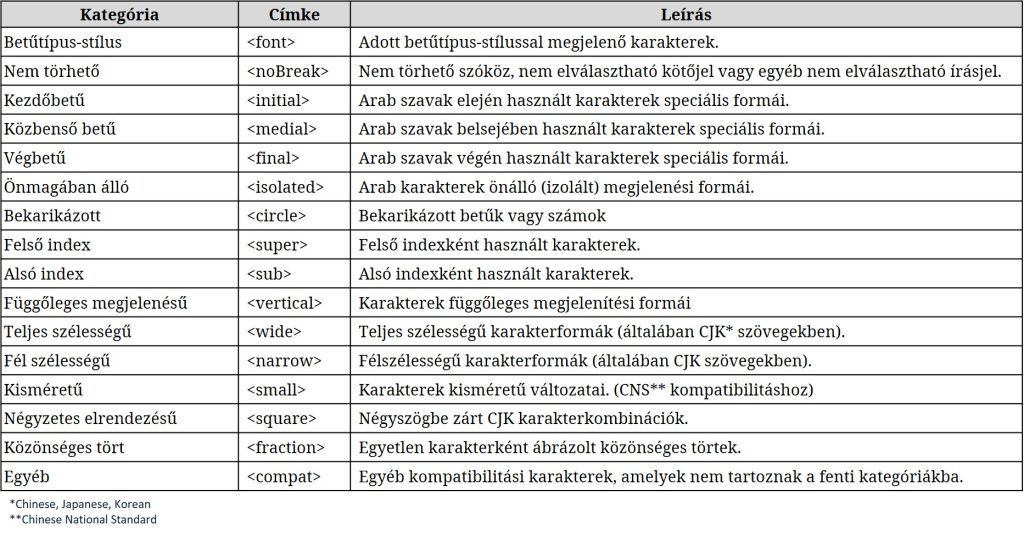
Ha meg akarjuk tudni, hogy egy adott karakterhez van-e hozzárendelt felbontás, és ha igen milyen, akkor az unicodedata modul decomposition() függvényét kell meghívni az adott karakterre. Az alábbi tesztprogramban néhány példát mutatunk. Ezek között szerepel a görög mű betű is, valamint az összes, korábban felsorolt ehhez hasonló karakter. Láthatjuk, hogy ez utóbbiak mindegyikének van felbontása, mégpedig kompatibilitási, ami minden esetben a U+03BC kódpontú görög mű betű.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
import unicodedata as ud test_chars = ['e', 'é', 'ä', 'ñ', 'Â', '₉', '⁹', '①', '¼', 'μ', 'µ', '𝛍', '𝜇', '𝝁', '𝝻', '𝞵'] print('{:^13}\t{:^46}{:^14}{:^14}{:^16}{}'.format('Karakterkép', 'Karakternév', 'Felbontás', 'Címke', 'Kódpontok', 'Karakterképek')) print(chr(0x2015) * 78) for char in test_chars: decomposition_list = ud.decomposition(char).split() # Ha a karaternek van felbontása és a felbontás kompatibilitás szerinti, akkor van '<...>' szerkezetű címke. # Ha kanonikus a felbontás, akkor nincs címke. if not decomposition_list: decomposition_type = 'Nincs' tag = '' elif '<' in decomposition_list[0]: decomposition_type = 'kompatibilis' tag = decomposition_list[0] del decomposition_list[0] else: decomposition_type = 'kanonikus' tag = '' decomposed_codepoints: str = ' '.join(decomposition_list) decomposed_str = str([chr(int(x, 16)) for x in decomposition_list]).strip('[]') output = '{:^11}\t\t{:46}{:17}{:12}{:18}{}'.format(char, ud.name(char), decomposition_type, tag, decomposed_codepoints, decomposed_str) print(output) # Karakterkép Karakternév Felbontás Címke Kódpontok Karakterképek # ――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――――― # e LATIN SMALL LETTER E Nincs # é LATIN SMALL LETTER E WITH ACUTE kanonikus 0065 0301 'e', '́' # ä LATIN SMALL LETTER A WITH DIAERESIS kanonikus 0061 0308 'a', '̈' # ñ LATIN SMALL LETTER N WITH TILDE kanonikus 006E 0303 'n', '̃' # Â LATIN CAPITAL LETTER A WITH CIRCUMFLEX kanonikus 0041 0302 'A', '̂' # ₉ SUBSCRIPT NINE kompatibilis <sub> 0039 '9' # ⁹ SUPERSCRIPT NINE kompatibilis <super> 0039 '9' # ① CIRCLED DIGIT ONE kompatibilis <circle> 0031 '1' # ¼ VULGAR FRACTION ONE QUARTER kompatibilis <fraction> 0031 2044 0034 '1', '⁄', '4' # μ GREEK SMALL LETTER MU Nincs # µ MICRO SIGN kompatibilis <compat> 03BC 'μ' # 𝛍 MATHEMATICAL BOLD SMALL MU kompatibilis <font> 03BC 'μ' # 𝜇 MATHEMATICAL ITALIC SMALL MU kompatibilis <font> 03BC 'μ' # 𝝁 MATHEMATICAL BOLD ITALIC SMALL MU kompatibilis <font> 03BC 'μ' # 𝝻 MATHEMATICAL SANS-SERIF BOLD SMALL MU kompatibilis <font> 03BC 'μ' # 𝞵 MATHEMATICAL SANS-SERIF BOLD ITALIC SMALL MU kompatibilis <font> 03BC 'μ' |
Normalizálás megvalósítása a progamkódban
Mindezek után a kérdés már csak az, hogy hogyan tudjuk egy karakter vagy karaktersorozat Unicode-normalizálását a programunkban elvégezni. Ehhez nem kell mást tenni, mint az unicodedata modul normalize() függvényét kell meghívni, átadva az adott karaktersorozatot mint második argumentumot. Visszatérési értékként a normalizált karaktersorozatot kapjuk.
Az eddig tárgyalt elvi alapok megismerésére nem csak azért volt szükség, hogy a decomposition() függvény célját értsük és tudjuk értelmezni a visszatérési értékét, hanem azért is, hogy a normalize() függvényt értsük és helyes tudjuk használni. Ugyanis első paraméterének meg kell adni egy konstanst, ami meghatározza, hogy a négy lehetséges normalizációs forma közül melyik alapján kívánjuk a normalizálást végezni. A konstans értékei ‘NFC‘, ‘NFKC‘, ‘NFD‘, ‘NFKD‘ lehetnek, amelyek a normalizációs formák angol nevéből képzett rövidítések, ahogy azt fentebb már láttuk.
De mi alapján döntsük el, hogy melyik normalizációs formát válasszuk? Más szóval, mi alapján határozzuk meg, hogy a normalize() függvény hívásához melyik konstanst kell átadni?
A választás alapja a cél és a kontextus. A Unicode-normalizáció célja mindig az, hogy azonosításhoz, összehasonlításhoz, kereséshez, tároláshoz megbízható, egységes reprezentációt kapjunk. Ezért a választást elsősorban az alkalmazás, a használati cél határozza meg. A következő táblázat ehhez ad néhány szempontot és javaslatot.
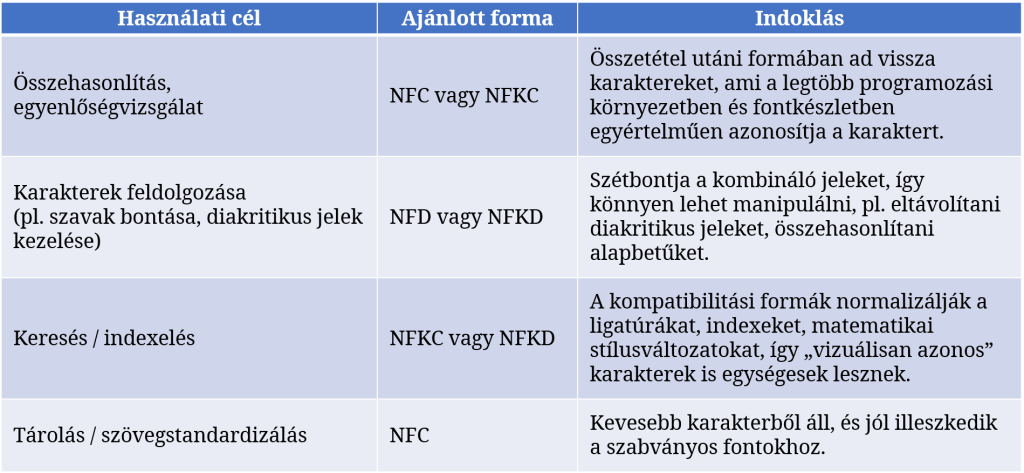
Most már visszatérhetünk az eredeti feladatunkhoz. Az SI előtaghoz tartozó tényezőt kiadó függvényünk esetében az argumentumként kapott karakterláncot, miután megtisztítottuk ez esetleges határoló szóközöktől, először normalizálni kell, és csak aztán lehet a szótárból kikeresni az ehhez tartozó szorzót. Mivel itt adott karakterláncra vonatkozó egyenlőségvizsálatot végzünk, ezért az NFKC normalizációs formát választjuk a normalize() függvény hívásához. Az így módosított függvény definícióját és a µ karakterekre vonatkozó tesztsorokat alább láthatjuk.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
import unicodedata as ud SI_PREFIXES = {'p': 1e-12, 'n': 1e-09, 'μ': 1e-6, 'm': 1e-3, 'c': 1e-2, 'd': 1e-1, 'T': 1e+12, 'G': 1e+09, 'M': 1e+6, 'k': 1e+3, 'h': 1e+2, 'da': 1e+1} def get_prefix_multiplier(prefix: str) -> float: # Szóközök eltávolítása. prefix = prefix.strip() # Unicode-normalizálás. prefix = ud.normalize('NFKC', prefix) # Az SI előtaghoz tartozó szorzó kikérése. if prefix in SI_PREFIXES: return SI_PREFIXES[prefix] raise ValueError(f'Nem érvényes SI előtag: {prefix}') for prefix_symbol in ('µ', 'μ', '𝛍', '𝜇', '𝝁', '𝝻', '𝞵'): try: print('{:2}{:46}\t{:.0e}'.format(prefix_symbol, ud.name(prefix_symbol), get_prefix_multiplier(prefix_symbol))) except ValueError as ve: print(ve) # µ MICRO SIGN 1e-06 # μ GREEK SMALL LETTER MU 1e-06 # 𝛍 MATHEMATICAL BOLD SMALL MU 1e-06 # 𝜇 MATHEMATICAL ITALIC SMALL MU 1e-06 # 𝝁 MATHEMATICAL BOLD ITALIC SMALL MU 1e-06 # 𝝻 MATHEMATICAL SANS-SERIF BOLD SMALL MU 1e-06 # 𝞵 MATHEMATICAL SANS-SERIF BOLD ITALIC SMALL MU 1e-06 |
Az eredmények visszaigazolják, hogy a függvény most már a tervezetteknek megfelelően, helyesen működik.
Ebben a bejegyzésben az Unicode karakterek és feldolgozásuk volt a középpontban. Az Unicode rendszer alapjainak ismerete nem csak az itt bemutatott példa megértéséhez, hanem a napi Python alkalmazásfejlesztéshez is nélkülözhetetlen. Ezért a Python tudásépítés lépésről lépésre című e-könyv már az elején, a „Unicode röviden” című részben ismerteti a legalapvetőbb tudnivalókat.